AI로 정적 페이지 옮겨오기
최종 수정: 2026년 7월 3일
여기서는 정적인 HTML로 작성된 페이지를 WEEGLOO가 관리하는 콘텐츠 기반 서비스로 옮기는 과정을 살펴봅니다.

이 도움말에서는 단일 공연 안내 페이지를 예제(다운로드)로 씁니다. 이 페이지는 공연 자체에 대한 정보와 함께 출연하는 아티스트 세 명의 정보를 담고 있고, 모든 데이터가 HTML 파일 안에 직접 적혀 있는 형태입니다. 이런 구조는 페이지를 처음 만들 때는 부담이 없지만, 출연자가 바뀌거나 공연 정보가 수정될 때마다 HTML 파일을 매번 직접 고쳐야 한다는 한계가 있습니다.
이번 단계에서는 LLM 에이전트와 WEEGLOO MCP를 함께 써서 세 가지 작업을 차례로 진행합니다. 먼저 정적 HTML 페이지를 분석해 알맞은 Content Type을 자동으로 만들고, 이어서 페이지 안에 적혀 있던 데이터를 뽑아 Content로 적재한 뒤, 마지막으로 페이지가 CDA를 통해 데이터를 가져오도록 코드를 고칩니다.
이 과정을 거치면 별도의 백엔드(데이터를 저장하고 처리하는 뒤편 시스템)를 직접 만들지 않고도, 기존 정적 페이지를 WEEGLOO 기반의 콘텐츠 서비스로 옮길 수 있습니다.
사전 준비
작업을 시작하기 전에 두 가지가 준비돼 있어야 합니다.
첫째, WEEGLOO에 새 Space가 비어 있는 상태로 만들어져 있어야 합니다. 앞으로 만들 Content Type과 Content가 모두 이 Space 안에서 관리되고, 비어 있는 상태에서 시작해야 흐름을 더 또렷이 따라갈 수 있기 때문입니다. Organization과 Space에 대한 자세한 내용은 접근과 권한에서 다룹니다.
둘째, LLM 에이전트가 WEEGLOO MCP에 연결돼 있어야 합니다. 이 도움말은 Cursor IDE를 기준으로 진행하지만, Claude Desktop처럼 MCP를 지원하는 환경이라면 같은 흐름으로 진행할 수 있습니다. 설치 방법은 MCP에서 다룹니다.
설치가 끝나면 LLM 에이전트가 WEEGLOO의 CMA(Content Management API)에 정의된 도구를 직접 호출할 수 있는 상태가 됩니다. 즉 사람이 콘텐츠 스튜디오에서 하던 Content Type 생성, Content 등록·발행 같은 작업을 LLM 에이전트가 자연어 요청만으로 수행할 수 있게 됩니다.
콘텐츠 모델링
가장 먼저 할 일은 페이지에 담긴 데이터의 구조를 Content Type으로 정의하는 것입니다. Content Type은 데이터의 설계도와 같아서, 어떤 Field를 가지는 데이터를 WEEGLOO에서 관리할지 미리 정합니다.
예제 페이지를 보면 공연 자체에 대한 정보(제목, 일시, 장소, 가격 등)와 출연자에 대한 정보(이름, 역할, 셋타임, 소개)가 함께 들어 있고, 두 종류의 데이터가 일대다 관계를 이룹니다. 그래서 이 페이지는 공연 정보를 담는 Content Type과 출연자 정보를 담는 Content Type, 두 가지로 자연스럽게 나뉩니다.
이 분석과 Content Type 생성은 LLM 에이전트에게 다음과 같이 요청하는 것만으로 자동으로 이루어집니다.
Hey, so there's an HTML file in the project — nightshift-2026.html. It's a
landing page for a one-night concert and right now everything's hardcoded
straight into the markup (the show details, the lineup, set times, all of it).
I want to migrate it over to Weegloo so the page can pull its content from
a CMS instead of having it all baked in. Let's take it step by step rather
than doing the whole thing in one go.
To kick things off, could you take a look at nightshift-2026.html and figure
out what content types would make sense for it, then go ahead and create
them in Weegloo? We'll deal with the actual content and the API wiring in
the following steps.요청을 받은 LLM 에이전트는 HTML 파일의 구조를 살펴 데이터의 종류와 관계를 추론하고, 각 Field에 어울리는 타입을 정한 뒤, WEEGLOO MCP로 Content Type을 만듭니다.
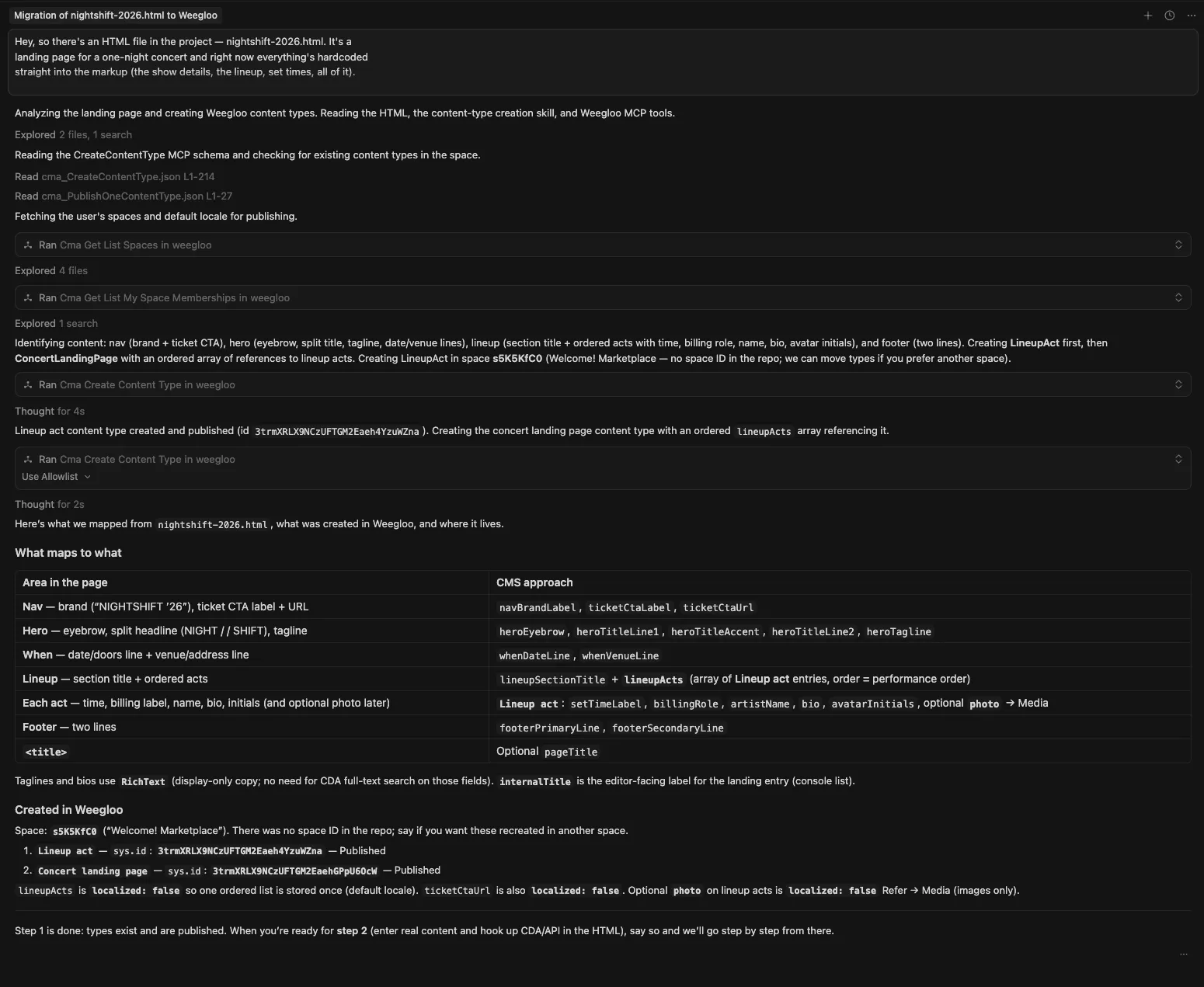
작업이 끝난 뒤 WEEGLOO 콘텐츠 스튜디오의 Content Type 페이지를 보면, 공연을 나타내는 Content Type과 출연자를 나타내는 Content Type 두 개가 새로 만들어진 것을 볼 수 있습니다. 공연 Content Type에는 제목·일시·장소·가격 같은 Field가, 출연자 Content Type에는 이름·역할·셋타임·소개와 함께 어떤 공연에 속하는지를 가리키는 참조(Reference) Field가 들어갑니다.
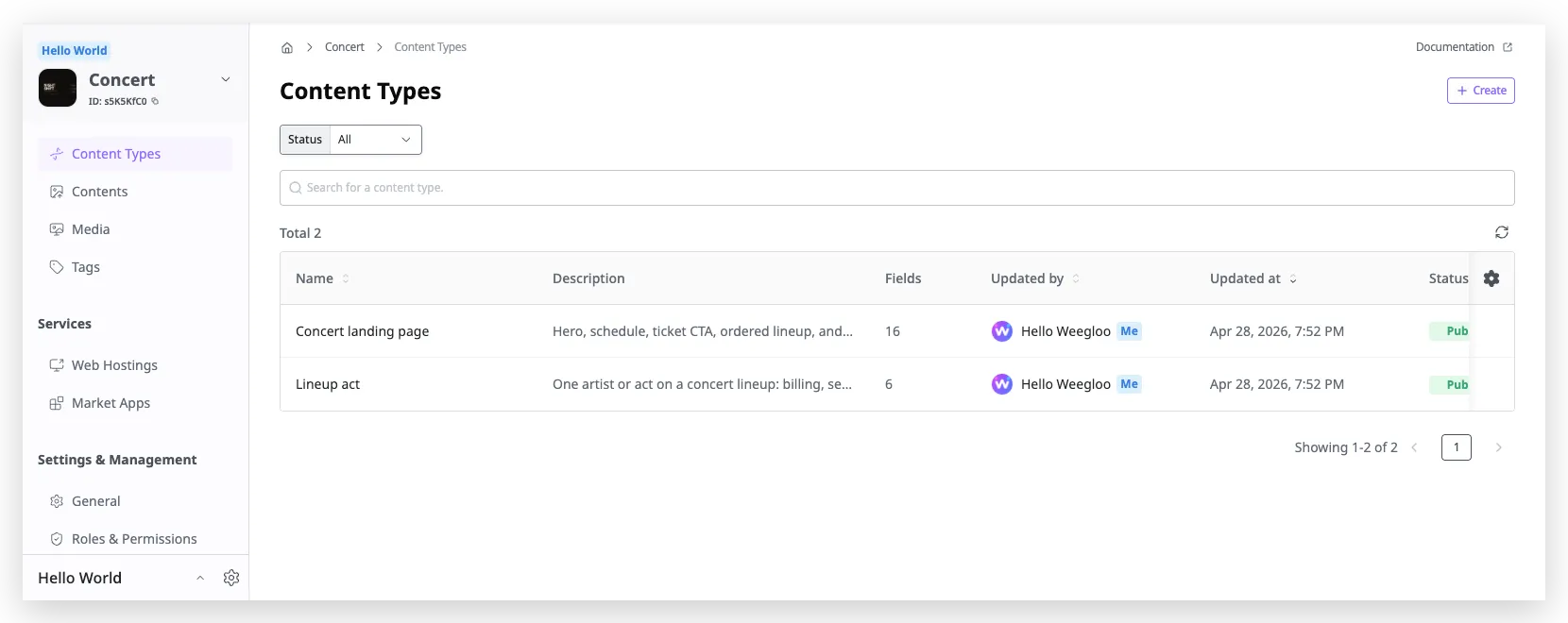
이렇게 Content Type이 정의되면 이 구조를 바탕으로 실제 데이터를 적재할 준비가 끝납니다. Content Type에 대한 자세한 내용은 Content 모델링에서 다룹니다.
콘텐츠 생성
Content Type은 데이터의 형식을 정의할 뿐, 그 자체에는 데이터가 들어 있지 않습니다. 이번 단계에서는 앞서 정의한 Content Type을 바탕으로, 페이지에 적혀 있던 실제 데이터를 Content로 옮깁니다.
LLM 에이전트에게 다음과 같이 요청하면, 페이지의 데이터를 분석해 Content Type에 맞는 Content를 만들고 발행까지 함께 처리합니다.
Alright, the content types look good. Now let's move on to actually loading
the data.
Could you go through nightshift-2026.html again, pull out the actual content
that's hardcoded in there, and create entries in Weegloo using the content
types we just made? Once everything's in, go ahead and publish them too so
they're ready to be served.요청을 받은 LLM 에이전트는 HTML을 다시 분석해 데이터를 항목별로 나눈 뒤, WEEGLOO MCP로 공연 정보 한 건과 출연자 정보 세 건을 등록합니다. 등록된 Content는 외부에서 조회할 수 있도록 함께 발행됩니다.
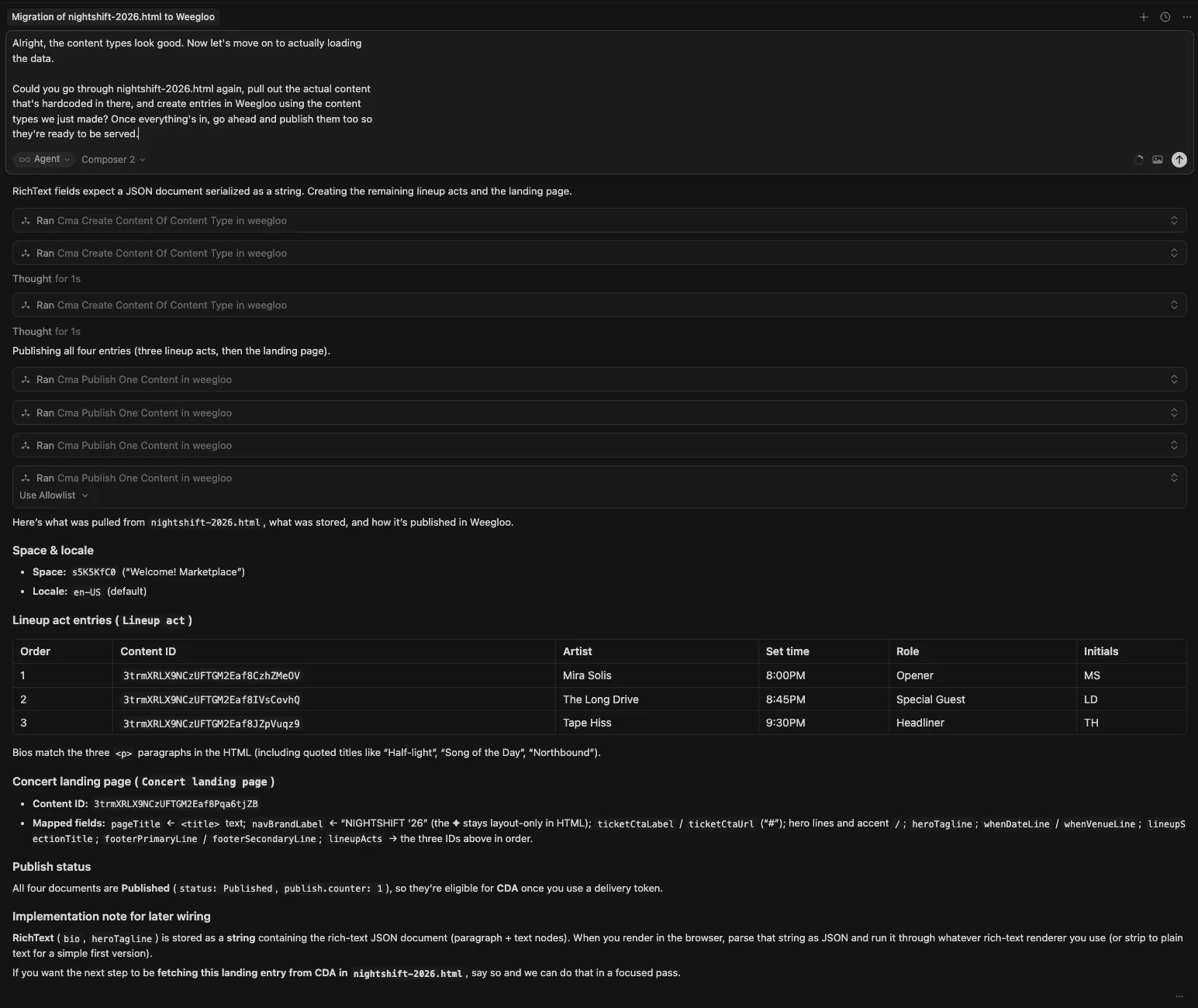
작업이 끝난 뒤 WEEGLOO 콘텐츠 스튜디오의 Content 목록을 보면, 공연 한 건과 출연자 세 건이 모두 발행된 상태로 등록돼 있습니다. 이때부터는 페이지의 코드를 직접 고치지 않아도, 콘텐츠 스튜디오나 LLM 에이전트로 데이터를 자유롭게 바꿀 수 있습니다.
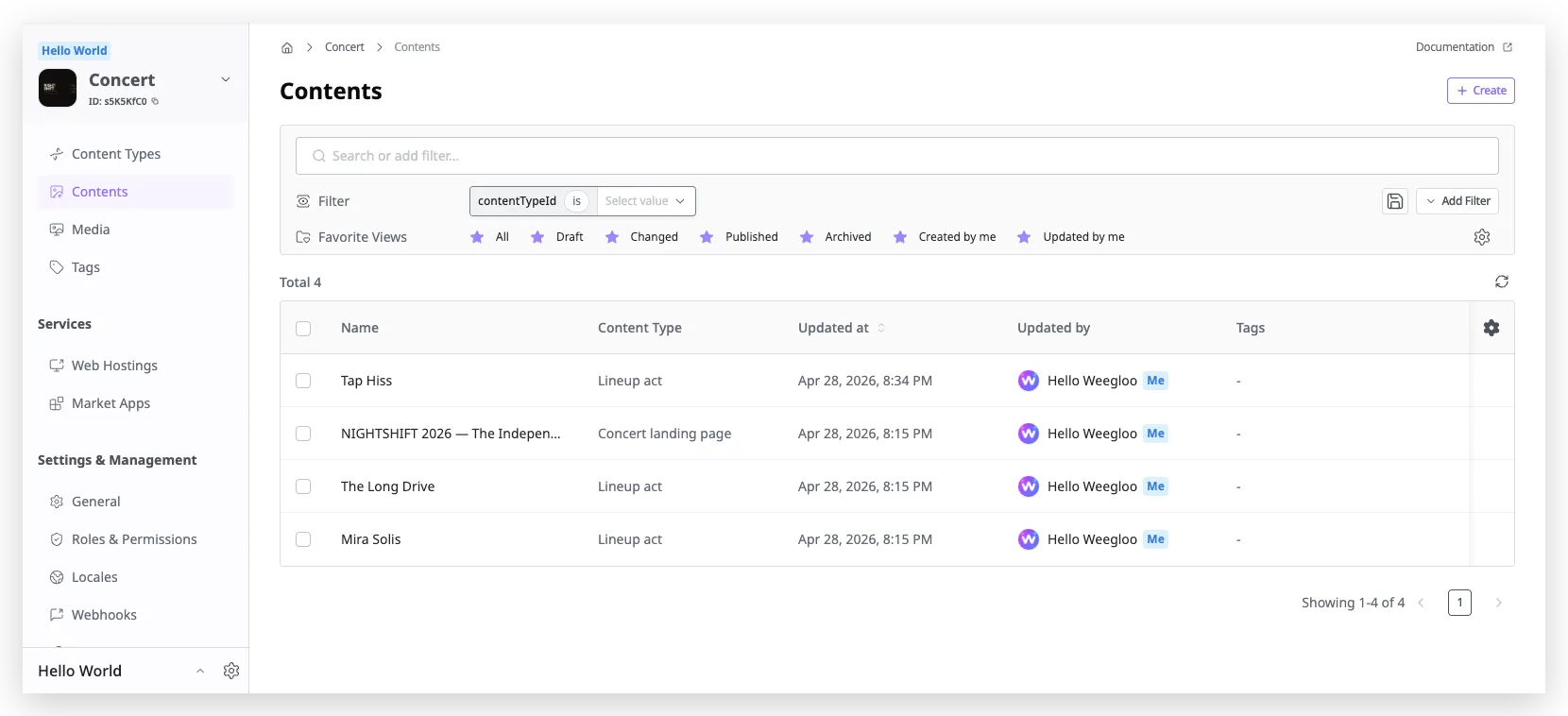
Content의 작성과 발행에 대한 자세한 내용은 Content 작성과 발행에서 다룹니다.
CDA 연동
데이터까지 준비됐다면, 마지막으로 페이지가 정적으로 적힌 HTML이 아니라 WEEGLOO의 CDA를 통해 데이터를 가져오도록 코드를 고칩니다. CDA는 발행된 Content를 외부 서비스에서 조회하도록 제공되는 읽기 전용 API로, 웹 페이지나 모바일 앱이 WEEGLOO의 데이터를 직접 가져와 쓸 수 있게 해 줍니다.
이 작업도 LLM 에이전트에게 다음과 같이 요청하면 자동으로 이루어집니다.
Okay, last step. The content's all in Weegloo and published, so now let's
hook the page up to actually use it.
Could you update nightshift-2026.html so that instead of having all that
data hardcoded in the markup, it fetches from Weegloo's CDA on load and
renders the page from the response? Basically the same page as before, just
pulling from the API now.요청을 받은 LLM 에이전트는 페이지에 박혀 있던 정적 데이터를 걷어 내고, 그 자리에 CDA 호출과 응답 데이터를 화면에 반영하는 코드를 채워 넣습니다. 출연자 정보가 있던 자리에는 출연자 Content 목록을 조회하는 CDA 호출이, 공연 정보가 있던 자리에는 공연 Content를 단건으로 조회하는 호출이 들어갑니다.
고친 페이지를 새로고침한 뒤 브라우저 개발자 도구의 Network 탭을 보면, 페이지가 로딩될 때 WEEGLOO의 CDA로 실제 요청이 보내지고 응답이 도착하는 것을 확인할 수 있습니다.
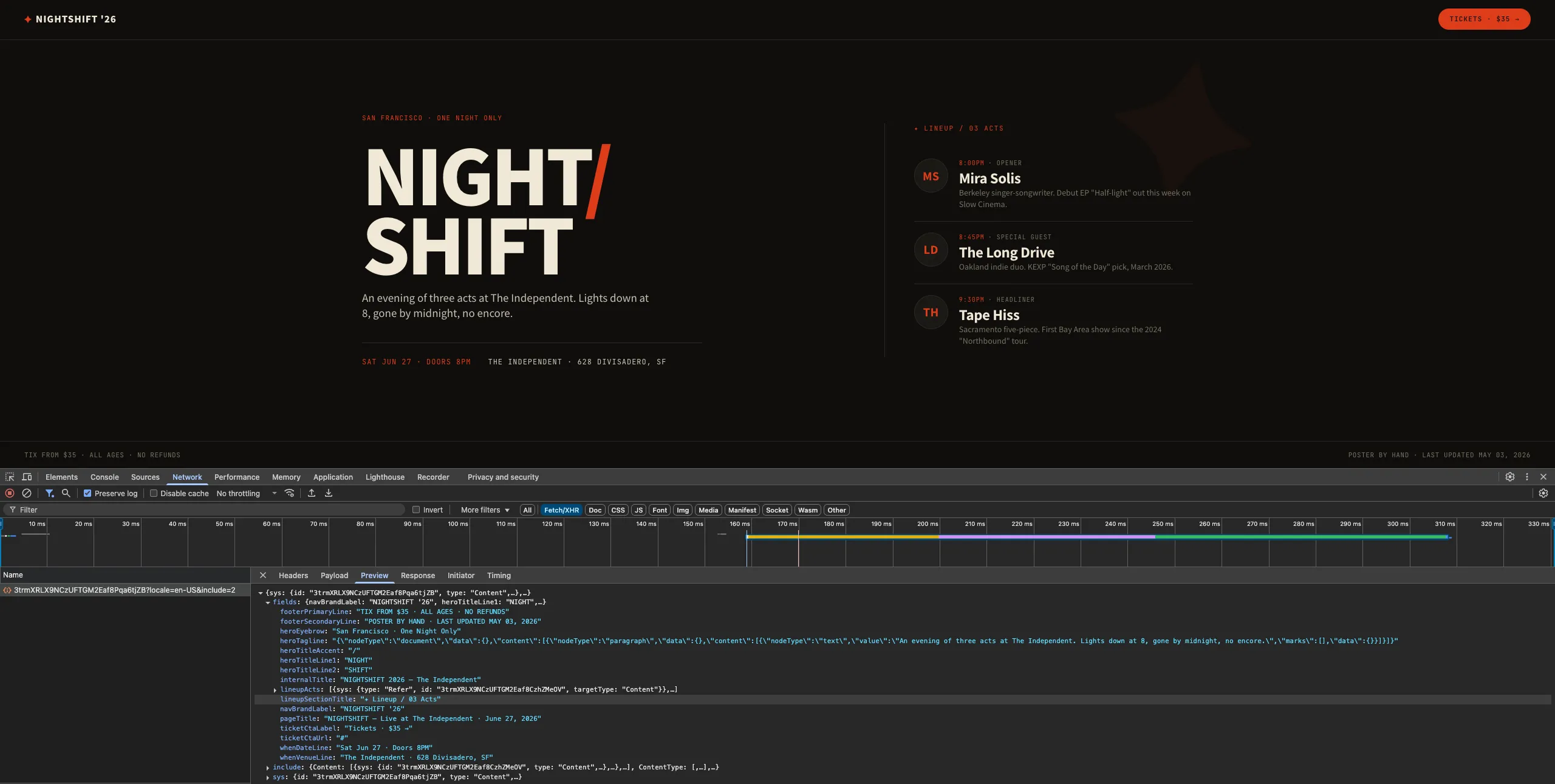
이제 WEEGLOO 콘텐츠 스튜디오에서 출연자의 셋타임을 바꾸거나 새 출연자를 추가한 뒤 페이지를 새로고침하면, 따로 빌드하거나 배포하지 않아도 바뀐 내용이 곧바로 반영됩니다. CDA에 대한 자세한 내용은 Content Delivery API에서 다룹니다.
지금까지 정적으로 작성돼 있던 단일 HTML 페이지를 WEEGLOO가 관리하는 콘텐츠 기반 서비스로 옮겨 봤습니다. 같은 흐름은 더 복잡한 페이지에도 그대로 적용할 수 있습니다. Content Type의 수와 Content의 양이 늘어날 뿐, 모델링과 적재, CDA 연동에 이르는 전체 과정은 똑같이 진행됩니다.